
“Mastering the game of Go without human knowledge” 라는 제목의 논문을 읽었다. 논문 리뷰 발표를 위해 제작한 자료를 기반으로 간략하게 글을 써본다.
https://github.com/suragnair/alpha-zero-general
GitHub - suragnair/alpha-zero-general: A clean implementation based on AlphaZero for any game in any framework + tutorial + Othe
A clean implementation based on AlphaZero for any game in any framework + tutorial + Othello/Gobang/TicTacToe/Connect4 and more - suragnair/alpha-zero-general
github.com
구글 딥마인드 소속의 David Silver가 네이쳐에 게재한 아티클로, 스스로 학습된 바둑 AI “알파제로”를 소개하고 있다.
Abstract를 읽어보면, 인간의 지식 없이 온전히 강화학습을 통해 학습된 알고리즘임에도 불구하고 기존의 alphaGo를 100:0으로 이기는 모습을 보여주었다고 한다. 기존의 알파고에 비해 4가지 차이점을 가지는데, 1. 랜덤 플레이에서 시작한 self-play 강화학습이다. 2. 인간의 데이터로 가공되지 않은 board state만 input으로 사용했다. 3. policy network와 value network를 따로 사용하지 않았다. 4. tree search가 더욱 간단하다.
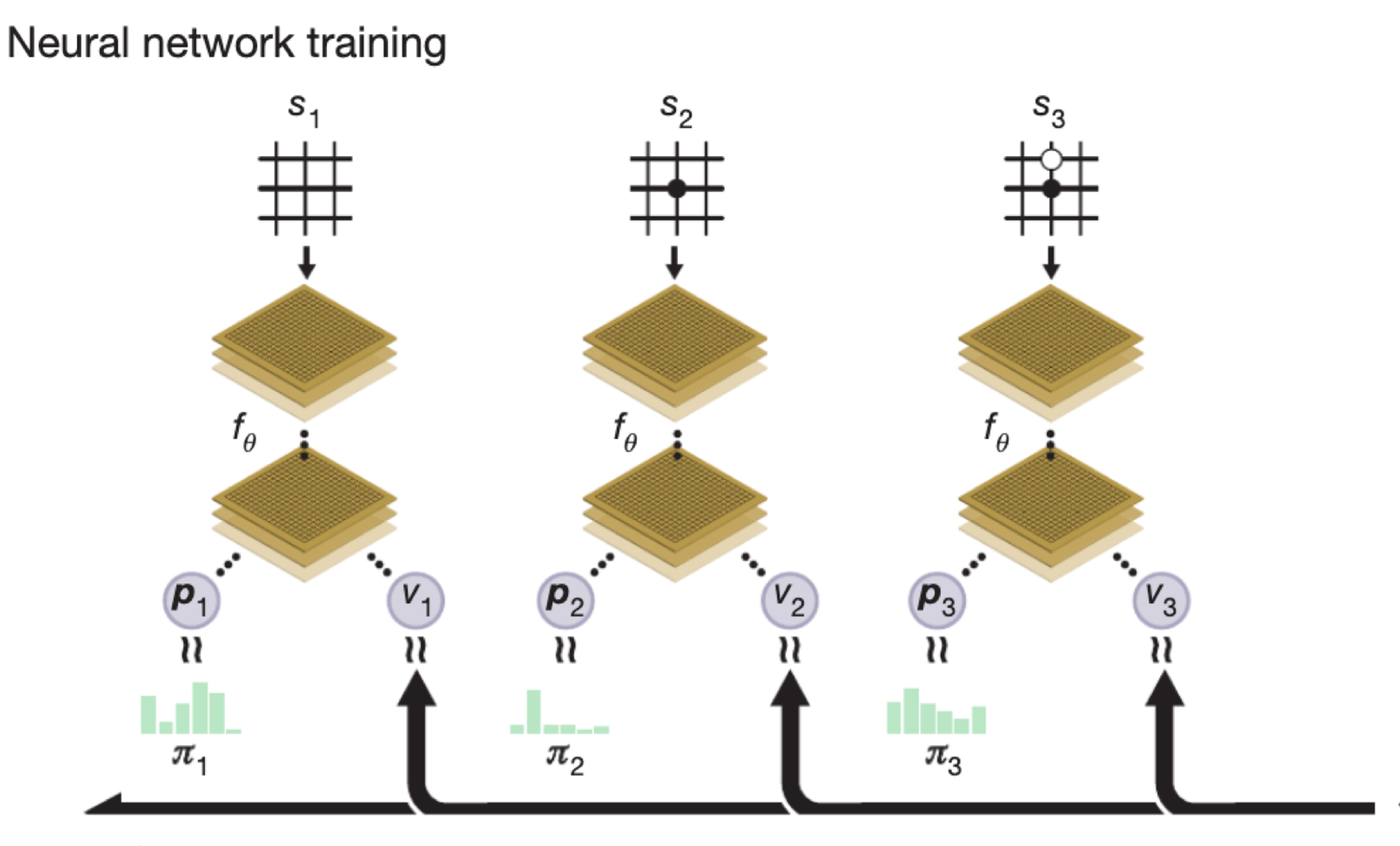
Board 상태를 input으로 받아 policy와 value를 출력하는 network를 학습시킨다. 그 와중에 MCTS를 사용하여 Policy를 evaluate하고 네트워크 학습 데이터를 수집한다.

우선 초기에는 랜덤 parameter (혹은 0으로 초기화 된) network가 있다.

이 network를 기반으로 MCTS를 진행한다. 이 트리는 각 노드에 N,W,Q,P라는 값을 가지고 있다. 각 노드에서 Q+U가 최대가 되도록 액션을 취할 것인데 Q는 해당 액션의 추정 밸류이고 U는 선택된 횟수가 적은 노드를 탐험하기 위한 항이다. 즉 최대한 높은 밸류의 액션을 고르면서도 탐험의 여지를 남겨두고 있다.
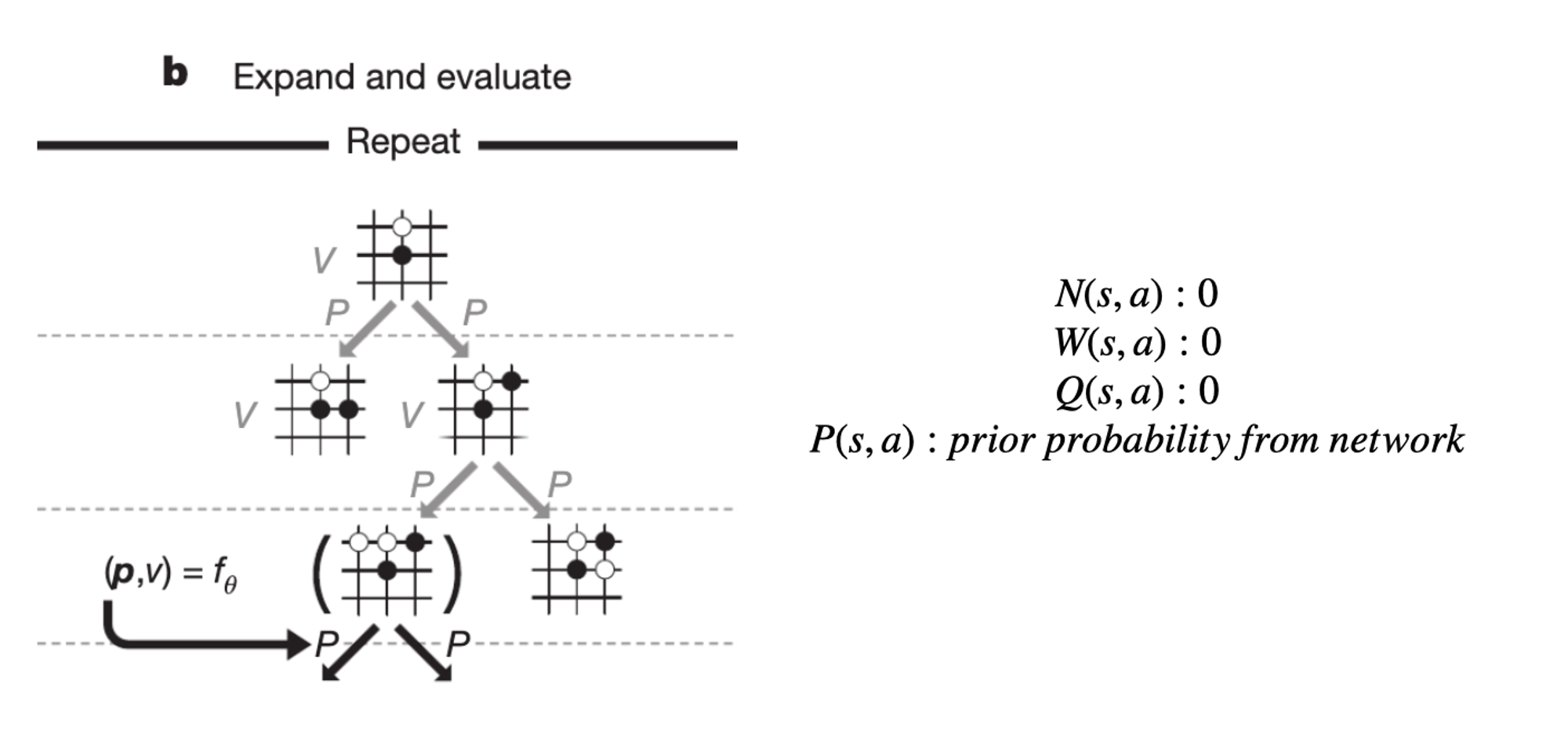
만약 탐험 과정에서 처음으로 방문하는 노드에 도착하면 network를 활용하여 policy를 가져오고 액션을 선택한다.

게임이 종료되면 승패에 따라 리워드를 획득하고 지나온 노드들에 대해 N,W,Q를 업데이트한다.
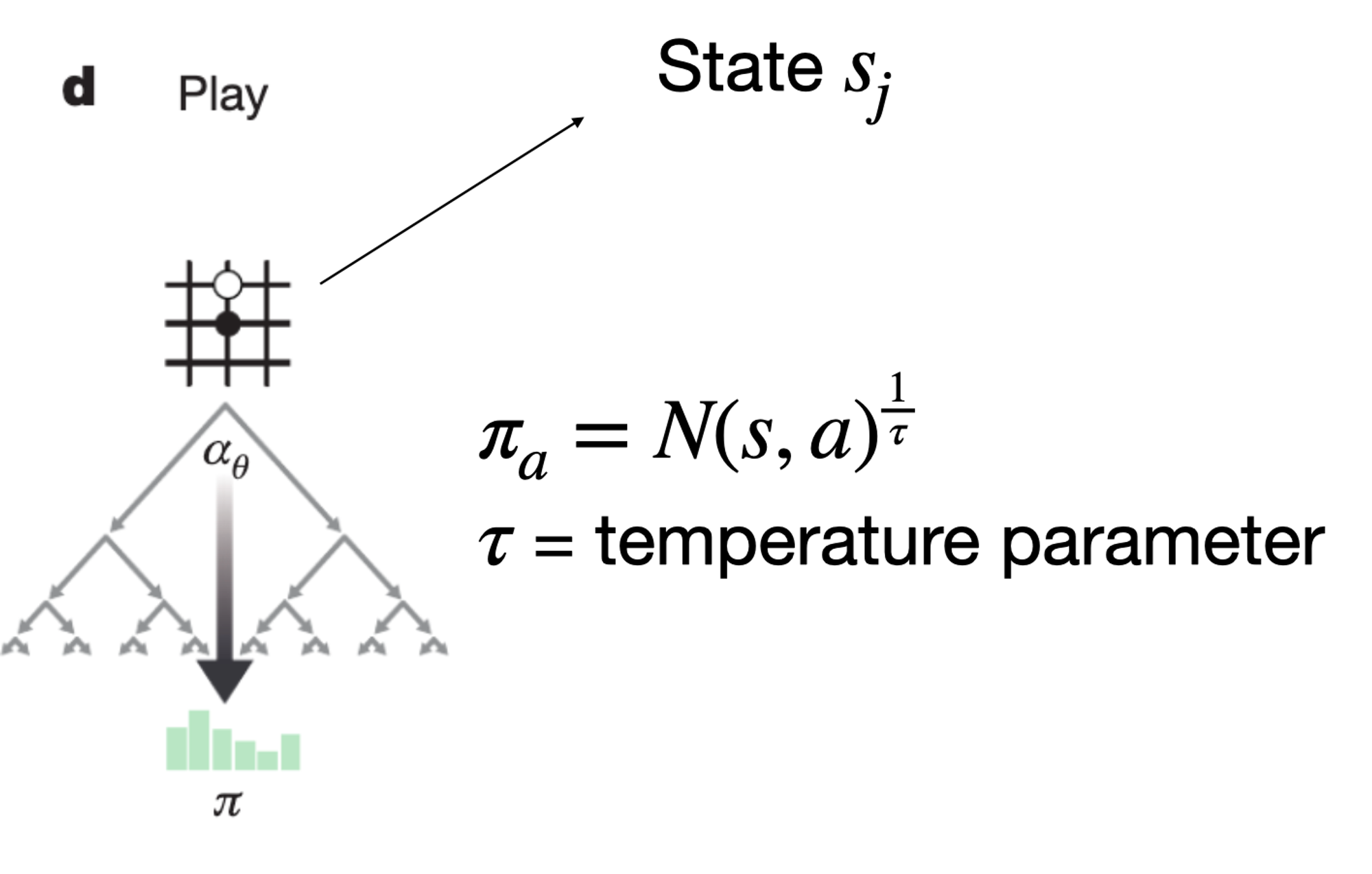
각 state에서 수 많은 시뮬레이션을 진행하여 액션에 대한 데이터를 수집한다. 이후 실제 액션을 선택해야하는데, 이는 각 액션의 (1/tau)제곱에 비례하는 확률로 선택한다. 이 때 tau는 temperature parameter이고 처음에는 1이었다가 점점 0에 가까워 진다. 즉, 초반에는 N에 정비례한 확률로 액션을 고르지만 시간이 지날수록 argMax a를 고르게 된다.

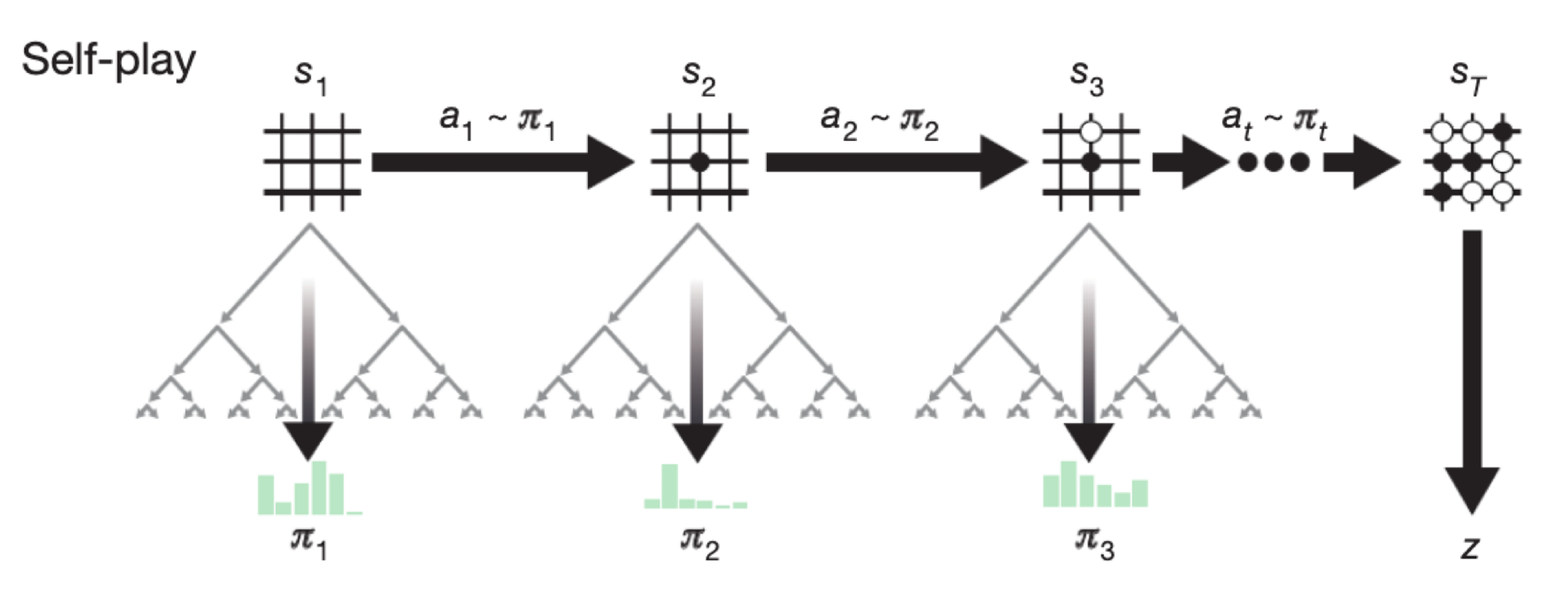
다시 큰 그림으로 돌아와서, 빈 보드판 s1에서 시작하여 각 액션을 고르기 위해 MCTS를 진행한다. a1을 골라 s2 상태가 되면 또 다시 MCTS를 진행하여 a2를 선택한다. 이렇게 게임 종료 상태에 도달하면 승패에 따라 z값을 얻게 되고, 지금까지의 (s, pi, z)를 모두 데이터 집합에 추가한다.
이 과정을 하나의 게임이라고 한다. 하나의 이터레이션 동안 400번의 게임을 진행하며 데이터를 수집한다.
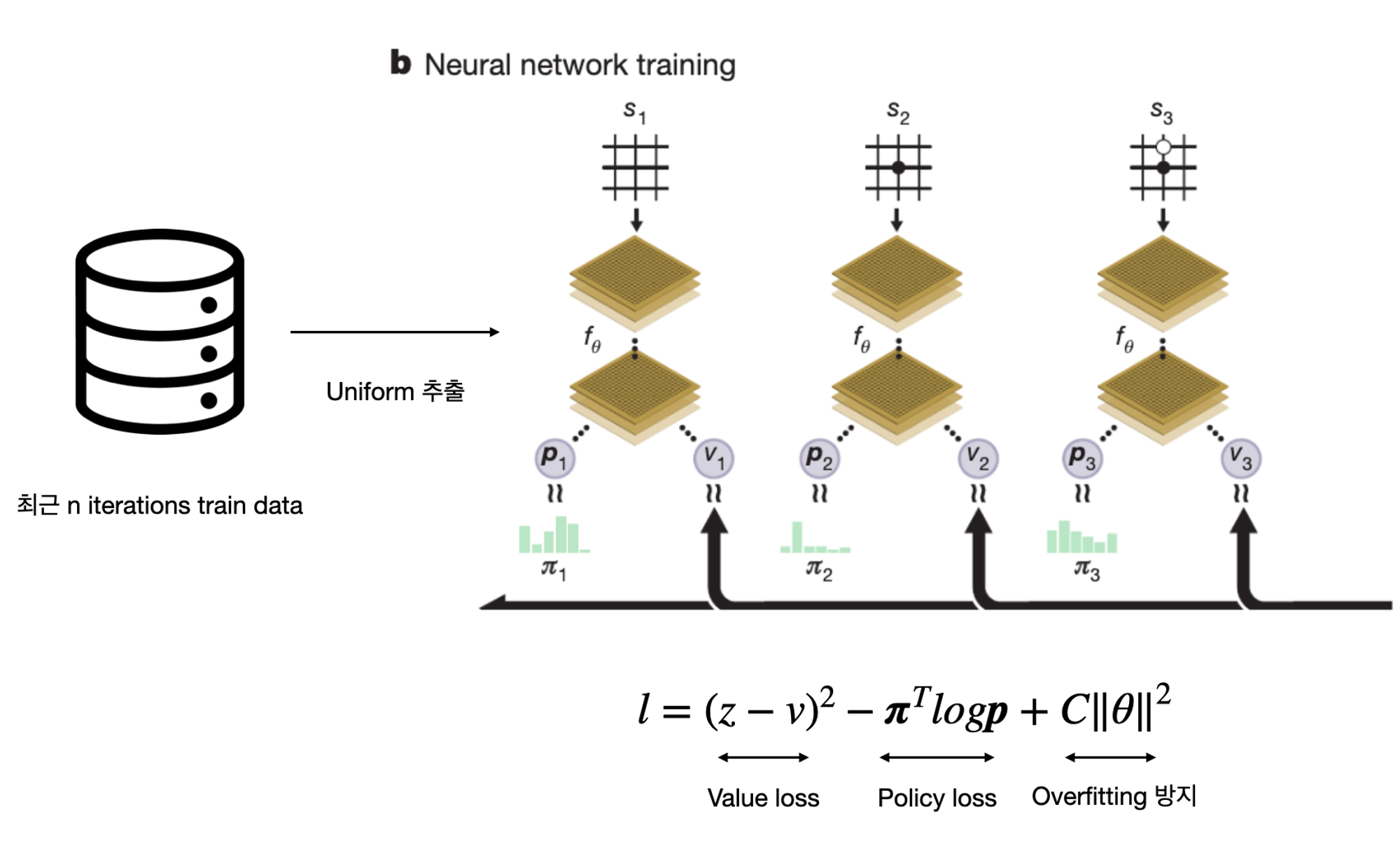
수집된 데이터를 collection에 저장한다. 학습 할 때에는 이 collection에서 uniform하게 데이터를 추출하여 데이터를 학습한다. 로스펑션은 사진의 수식과 같다.
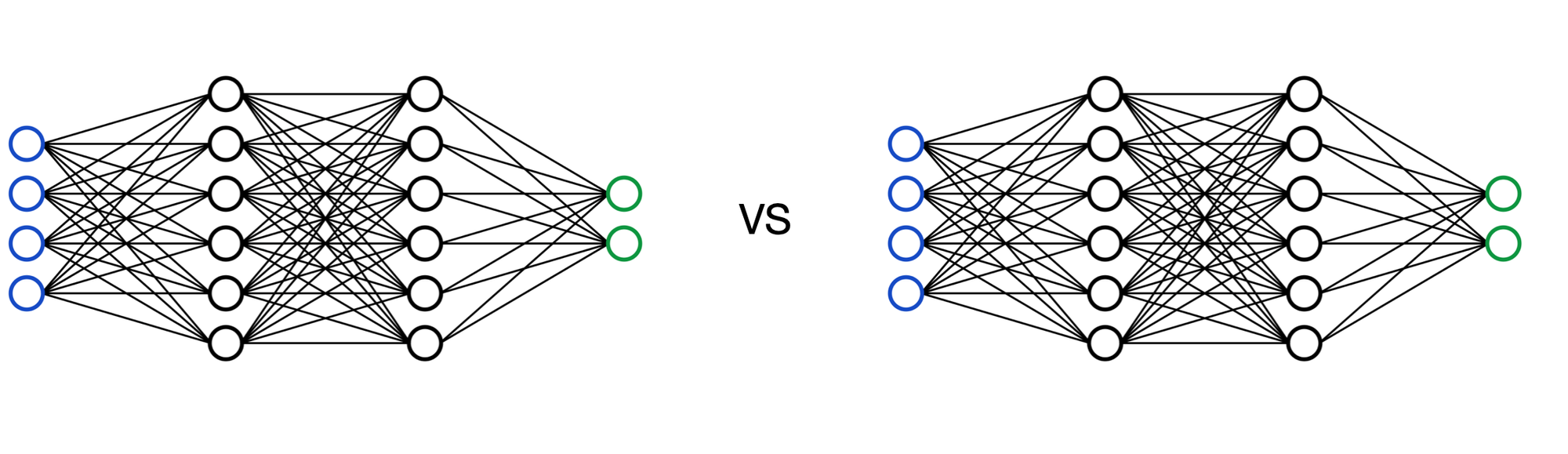
새로운 네트워크와 기존의 네트워크를 대결시켜, 높은 승률을 기록한다면 네트워크를 교체한다. 이제 다시 처음으로 돌아가 기존의 과정을 반복한다.
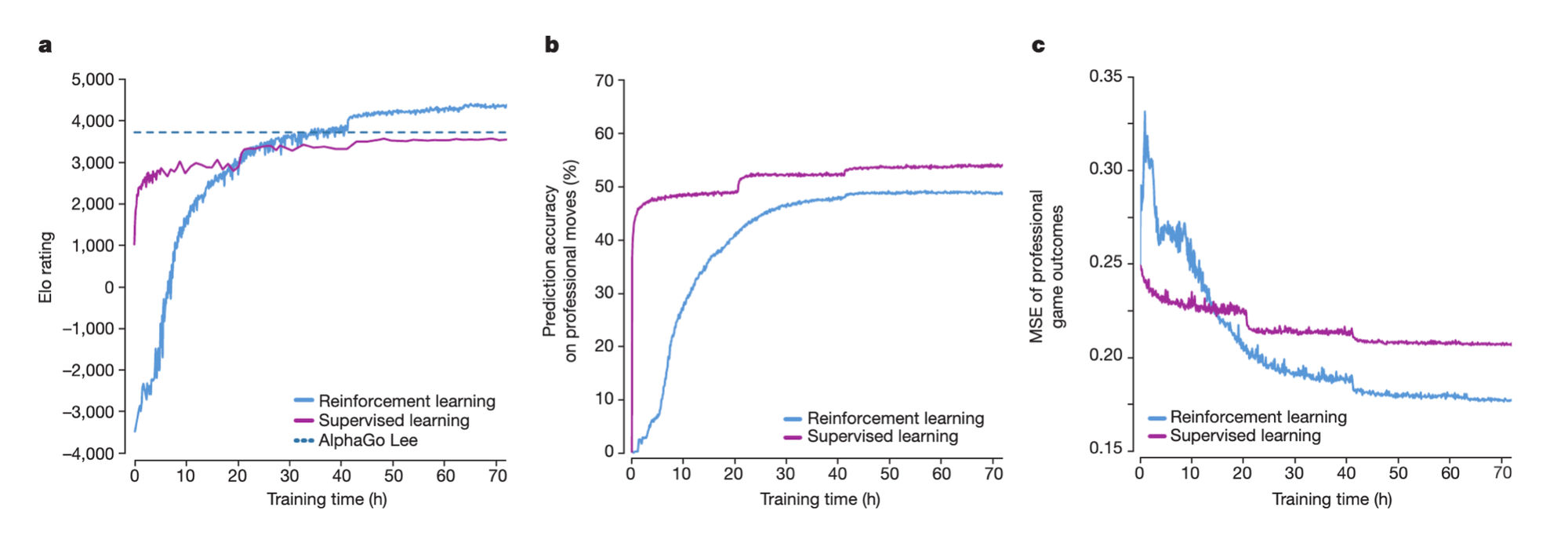
더 많은 자원으로 수 개월 학습된 AlphaGo Lee를 36시간만에 elo 측면에서 추월했다. Human Professional moves를 기반으로 action을 예상했을 때 Zero의 액션을 더 예상하기가 어려웠는데, 이는 창의적인 플레이를 많이 했다는 뜻이다. 마지막 그래프는 알파고가 인간의 수를 보고 승패를 예측하였을 때의 오차를 나타내는 것인데 Zero가 더 잘 맞혔다.
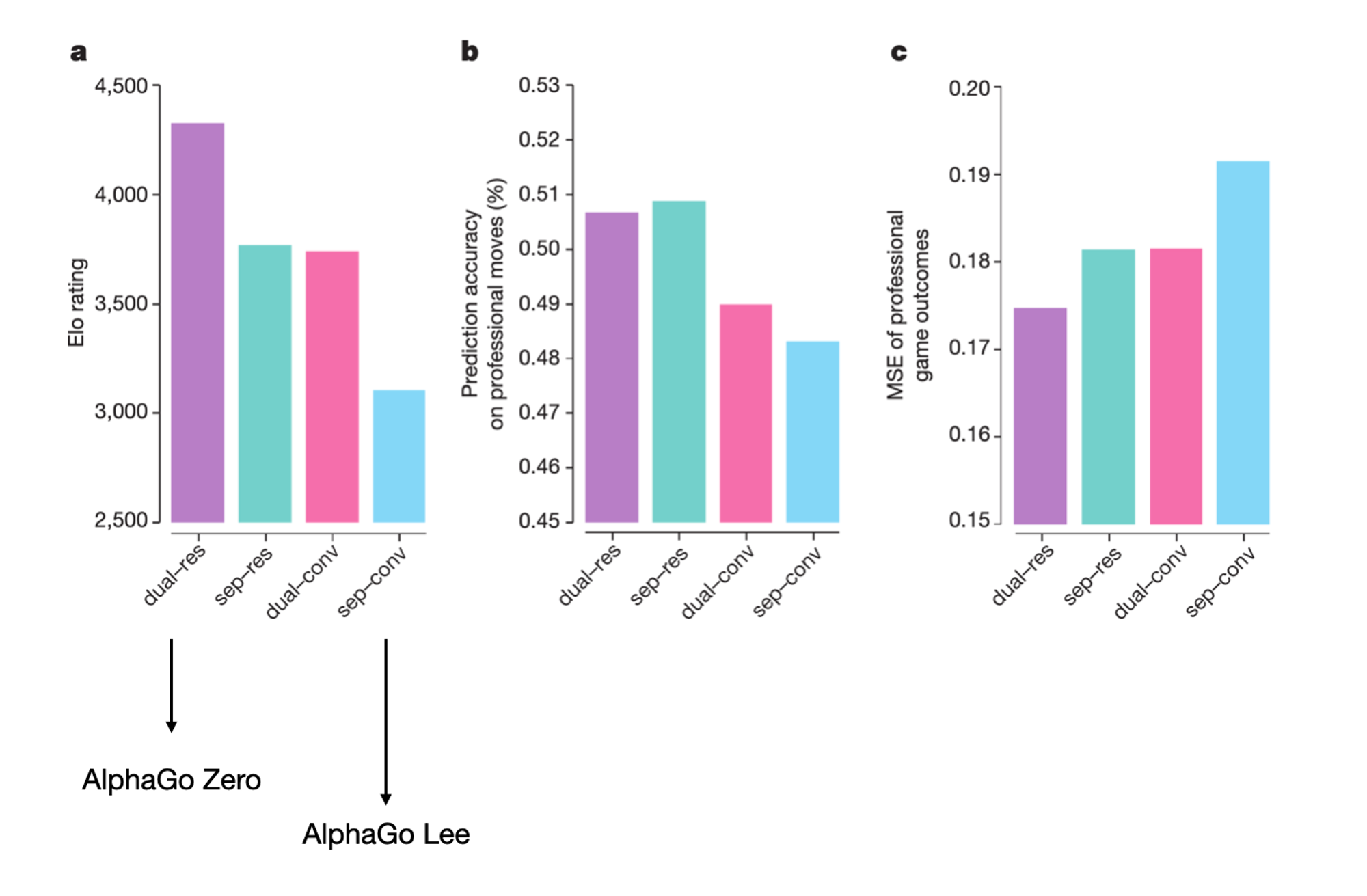
policy network와 value network를 분리한 것이 sep, 합친것이 dual이다. 또한 residual network를 사용하였으면 res, 그렇지 않으면 conv이다. 기존의 AlphaGo Lee (이세돌과 전투)는 sep-conv였고 이번 AlphaGo Zero는 dual-res인데, 더 높은 elo를 보여주었고 예측 오차도 적었다.
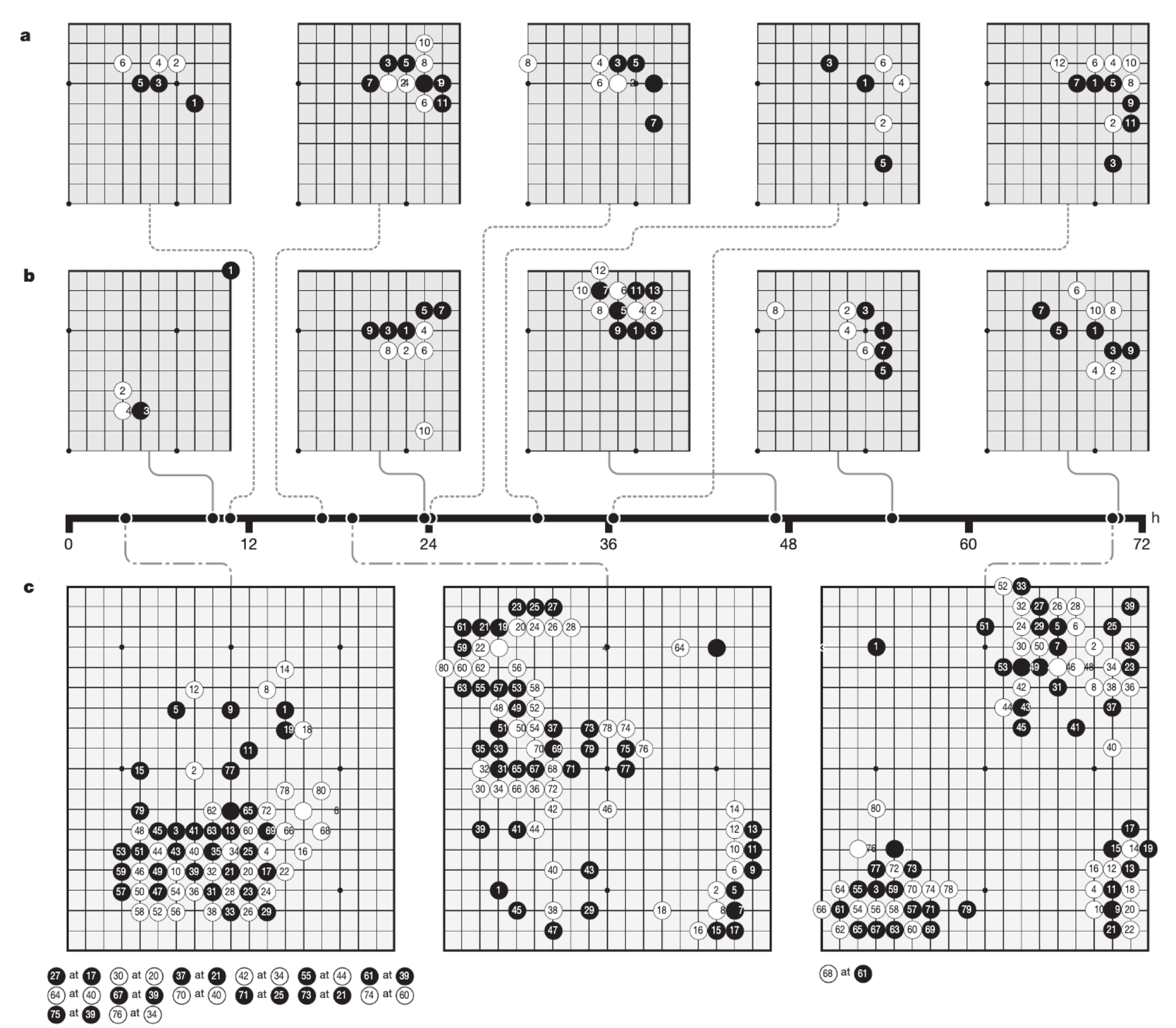
알파고는 학습 시간이 지나며 인간의 정석 테크닉들을 학습하는 모습을 보여주었다고 한다. 그 과정에서 인간은 쉽게 학습한 테크닉을 알파고가 늦게 학습하는 경우도 있었지만, 결론적으로 랜덤 액션에서 시작하였음에도 불구하고 빠른 속도로 학습하는 모습을 보여주었다.

alpha-zero의 코드를 포크하여 쿼리도라는 보드게임에 적용시켜 보았다. 원래는 9x9의 게임이지만 서버 자원의 부족으로 인해 5x5 게임판과 3개의 벽으로 축소하여 학습하였다.
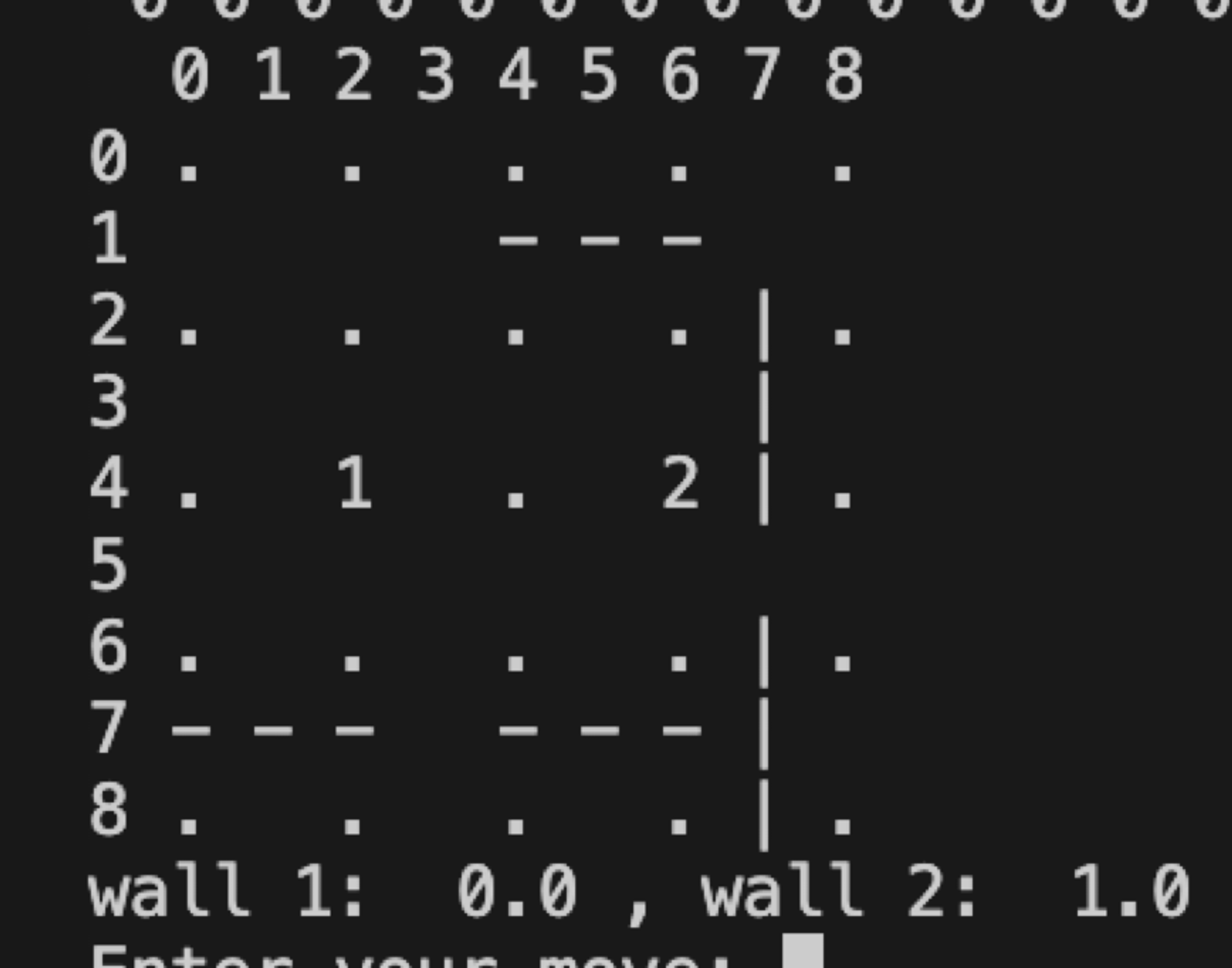
이렇게 직접 사람과 게임을 뜰수 있게 만들었는데, 24시간 정도 학습하고 나니 나보다는 훨씬 뛰어난 ai가 되었다. 물론 9x9를 학습시켜봐야 알겠지만 충분히 효과적인 모델이었다.

부록. 위와 같은 parameter로 학습했다.
'개발 인생 > ML' 카테고리의 다른 글
| LACI-QD 구현기 (1) | 2025.01.03 |
|---|---|
| DQN 논문 (Playing Atari with Deep Reinforcement Learning) 리뷰 (0) | 2024.06.20 |
| 벨만 방정식 (Bellman Expectation, Bellman Optimality) (0) | 2024.06.18 |
| 핸즈 온 머신러닝 :: 16. 강화 학습 (0) | 2020.02.02 |
| 핸즈 온 머신러닝 :: 15. 오토인코더 (0) | 2020.01.31 |