
Playing Atari with Deep Reinforcement Learning 논문에 대한 간략한 리뷰이다. 구글 딥 마인드에서 2013년 작성하였다.
https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
개요
Q-learning을 변형하여 convolutional neural network를 학습한 모델이다. 입력으로는 raw pixels를 사용하고 출력으로는 value function을 사용하였다. 7개의 아타리2600 게임에 적용하여 6개 게임에서 이전 접근 방식보다 뛰어난 성능을 보였고 3개 게임에서 인간보다 뛰어났다.
배경 지식
Q-learning에 대한 기본적인 배경 지식을 알고 있으면 좋다.
각 시간 단계에서 에이전트는 action set 에서 행동을 선택하며, 에뮬레이터에 전달되어 내부 상태와 게임 점수를 수정한다. 일반적으로 환경 E는 확률적이다. 에이전트는 에뮬레이터의 내부 상태를 관찰하지 못하고 관측 결과만을 알 수 있다. 또한 게임 점수의 변화를 나타내는 보상 r을 받는다. 하지만 특정 액션이 보상에 직결되는 것이 아니라 매우 이후의 보상에 연관되었을 수 있으므로 어려운 문제이다.
에이전트의 목표는 미래 보상을 극대화 하는 방식으로 행동을 선택하는 것으로, 미래 보상이 시간 단계마다 할인 된다는 가정을 가지고 있다.

최적 행동 가치함수 Q*(s,a)는 어떤 전략을 따를 때 달성할 수 있는 최대 기대 수익으로 정의되며 벨만 방정식을 따른다. 많은 강화 학습 알고리즘의 기본 아이디어는 벨만 방정식을 따라 반복 업데이트를 통해 함수를 추정하는 것이다. 본 논문에서는 신경망에 따라 함수를 추정했다.
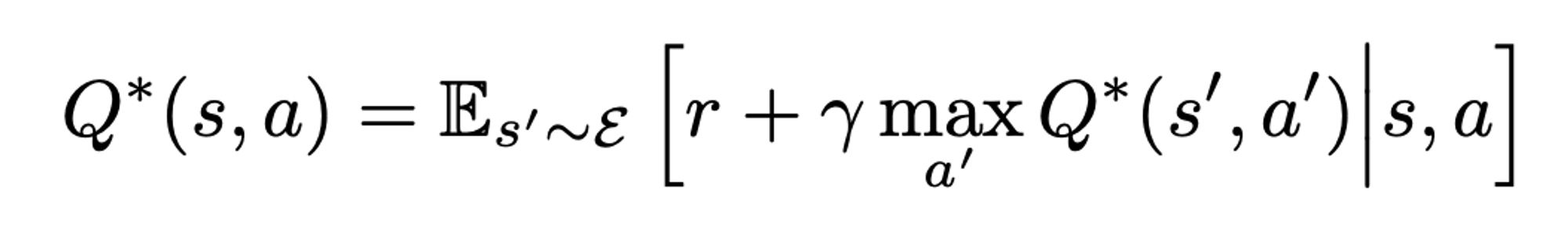
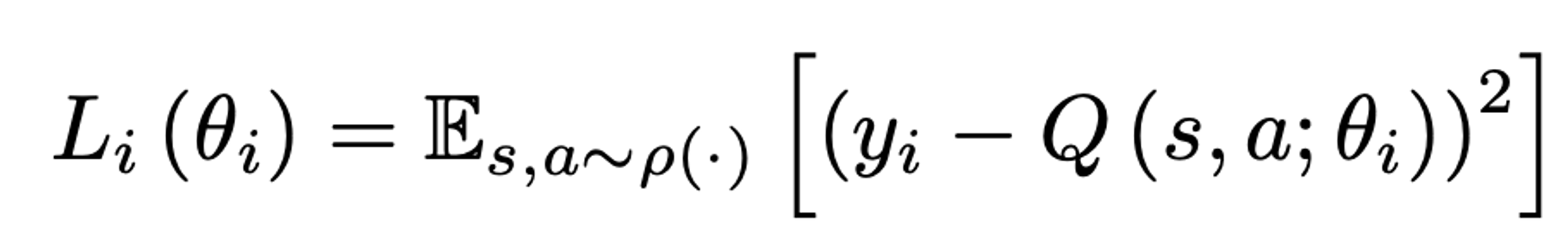
이 알고리즘은 샘플만을 따라 학습하므로 model-free이며, Q value에 따라 행동을 결정하므로 off-policy 이다.
알고리즘

상태를 관측하여 약간의 전처리를 통해 input으로 사용한다. 각 state에서 낮은 확률로 랜덤 action을 택하고, 그렇지 않은 경우 Q value가 가장 높은 action을 통해 실행하여 reward를 얻는다. 이 데이터를 리플레이 버퍼에 넣고, 전체 리플레이 버퍼에서 일부분의 데이터를 꺼내 경사하강법으로 학습한다.
이 방식은 standard online Q-learning에 비해 몇 가지 장점이 있다. 데이터가 여러 번 반복되어 학습에 사용될 수 있어 효율적이고, replay buffer를 사용했기 때문에 샘플 간의 상관관계에 영향을 덜 받는다. 만약 on-policy 학습 시 현재의 행동이 샘플 수집에 영향을 끼치므로 발산하거나 local optima에 빠질 수 있으므로 replay buffer를 사용하여 off-policy 학습을 해야한다.
성능
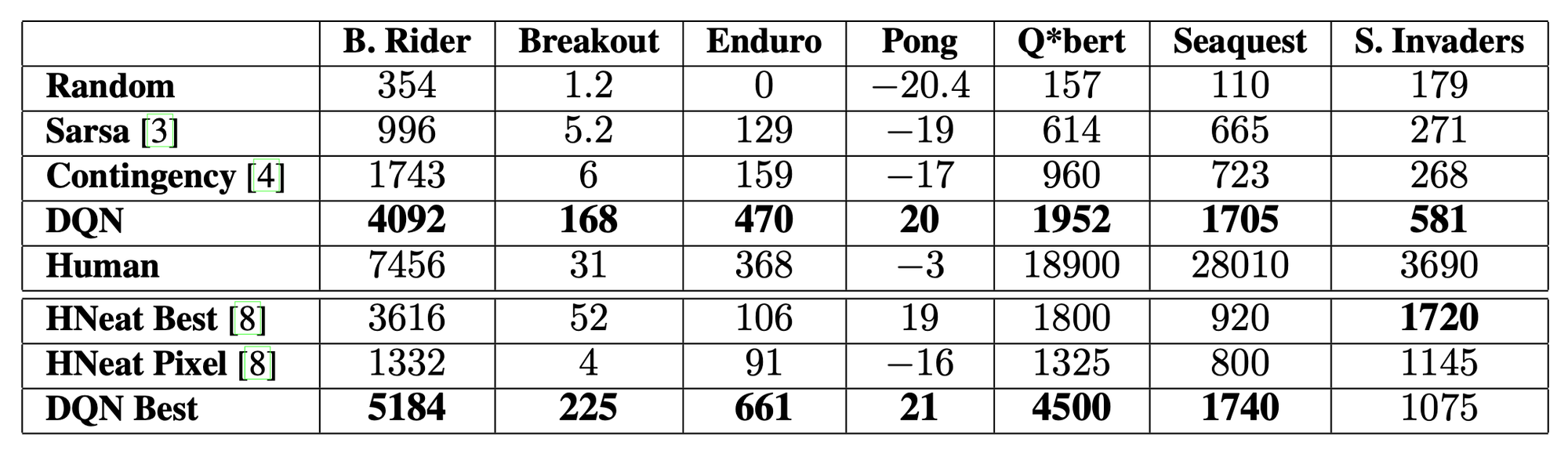
7개의 Atari 게임에 대해 위와 같은 성능을 보였다. 기존의 알고리즘 중 사전 지식을 가지고 화면 색상을 처리한 알고리즘이 있었던 반면, DQN 모델에 대해서는 raw input만을 사용했다. 그럼에도 불구하고 Breakout, Enduro, Pong에서 Human 보다 좋은 성능을 달성했다.
후기
강화학습을 공부 할 때에는 교과서에 있는 내용이니까 당연하다고 생각했었는데, 평소에 우리가 수학이나 국어를 배울 때와 달리 비교적 최근에 나온 논문에서 개념이 등장하고 이를 수업에서 배우게 된다는 사실이 미묘했다. 이 논문을 읽으며 다양한 기계학습 개념을 공부할 수 있었는데, Loss function, Sarsa, replay mechanism, Bell equation 등이 그 예시이다.
'개발 인생 > ML' 카테고리의 다른 글
| LACI-QD 구현기 (1) | 2025.01.03 |
|---|---|
| 알파제로 논문 리뷰 (0) | 2024.06.19 |
| 벨만 방정식 (Bellman Expectation, Bellman Optimality) (0) | 2024.06.18 |
| 핸즈 온 머신러닝 :: 16. 강화 학습 (0) | 2020.02.02 |
| 핸즈 온 머신러닝 :: 15. 오토인코더 (0) | 2020.01.31 |